Redefining Text Analytics with Advanced Layout Preservation
Traditional text analytics and information extraction systems often rely on plain text extracted from documents to apply machine learning and natural language processing techniques. However, this approach has a significant limitation: it ignores the complex textual layouts, orientations, and tabular structures inherent in PDF files and other layout-aware formats like MS Office documents. As a result, valuable contextual information is lost, potentially leading to inaccuracies and incomplete insights.
AgileDD takes a different approach. Our platform builds a uniform internal representation of any input document format, preserving the precise location of every single character within the document. Whether the characters are obtained through OCR or already exist in a text PDF or MS Office document, AgileDD ensures that the spatial relationships between elements are maintained.
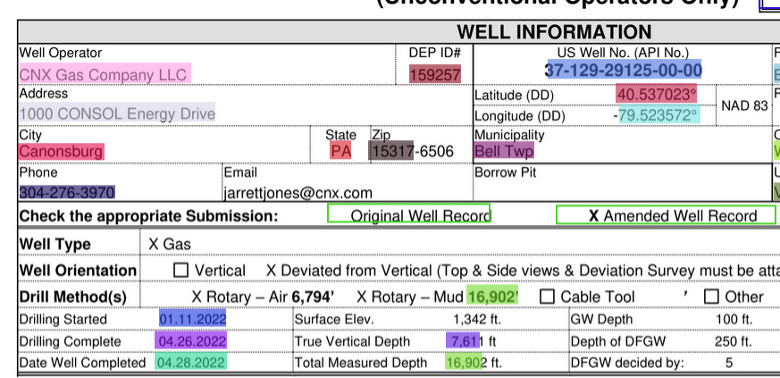
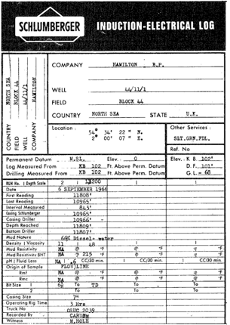
What sets AgileDD apart is its exceptional proficiency in capturing visual artifacts from forms with unmatched precision. No detail goes unnoticed, ensuring that your captured data is comprehensive and reliable. Plus, AgileDD offers the flexibility to seamlessly integrate with your existing systems via APIs or the option to install the platform in your private cloud or data center. This means your sensitive documents remain securely within your organization’s control, giving you peace of mind.
Say goodbye to the frustrations of inaccurate form data capture and hello to a new era of efficiency and reliability with AgileDD. Experience the difference for yourself and unlock the true potential of your form data.
This superior layout-aware method empowers AgileDD to capture textual metadata, tabular data, page classifiers, and semantic analysis of page content with unparalleled accuracy, regardless of the model used. By preserving the document’s original structure, AgileDD enables a deeper understanding of the information within, leading to more precise and comprehensive insights.
Moreover, AgileDD’s layout preservation capabilities extend to document querying, utilizing a powerful combination of Retrieval-Augmented Generation (RAG) and Large Language Models (LLM).
This innovative approach allows users to search for information within documents while considering the spatial relationships between elements, resulting in more accurate and contextually relevant results.